手机也能跑!微软27亿小模型击败Llama 2,让你的手机实现超强性能!

作者 | 程茜
编辑 | 李水青
智东西12月13日报道,昨日晚间,微软又亮出了小模型大招!
微软发布了27亿参数规模的小语言模型Phi-2,经研究人员测试,Phi-2在参数规模小于130亿的模型中展示了最先进性能。
从性能表现看,Phi-2在Big Bench Hard(BBH)、常识推理、语言理解、数学和编码基准测试中,其平均性能得分已经超过70亿、130亿参数规模的Mistral和Llama 2,在部分基准测试中超过谷歌的Gemini Nano 2。
Phi-2还有一大优势是,因为参数规模足够小,其可以在笔记本电脑、手机等移动设备上运行。
过去几个月间,微软研究院的机器学习基础团队陆续发布了小型语言模型(SLM)Phi系列。
其中,第一个模型为13亿参数规模的Phi-1,官方博客称,Phi-1在SLM中的Python编码方面表现最好,在HumanEval和MBPP基准测试上尤甚。第二个模型为13亿参数规模的Phi-1.5,这个模型的重点为常识推理和语言理解能力。
现在微软发布的Phi-2能为研究人员探索机器可解释性、安全性改进或对各种任务的微调实验上提供帮助,目前,Phi-2已经从Azure AI Studio模型目录中开放给研究人员。
一、96块A100 GPU训练14天,参数规模仅27亿一些大模型的参数规模达到数千亿的量级,使得其涌现出众多新兴能力,那么,是否可以通过改变训练策略等方式让更小的参数实现这些能力?微软的小型语言模型(SLM)系列或许是这一问题的答案。
Phi-2是一个基于Transformer架构的模型,具有下一个单词预测目标,在用于NLP和编码的合成数据集和Web数据集的混合上多次传递的1.4T tokens上进行训练。
Phi-2在96个A100 GPU上训练了14天,作为一个基础模型,其没有通过人类反馈强化学习(RLHF)进行对齐,也没有进行指令微调。
尽管如此,与经过调整的现有开源模型Llama 2-7B相比,研究人员观察到在避免生成有攻击性、有害和内容有偏差方面Phi-2的表现也不差。
研究人员根据ToxiGen的13个人口统计数据计算的安全评分,他们选择6541个句子的子集,并根据困惑度和句子“毒性”进行0到1之间的评分。分数高就说明,模型产生有攻击性、有害句子的可能性较小。
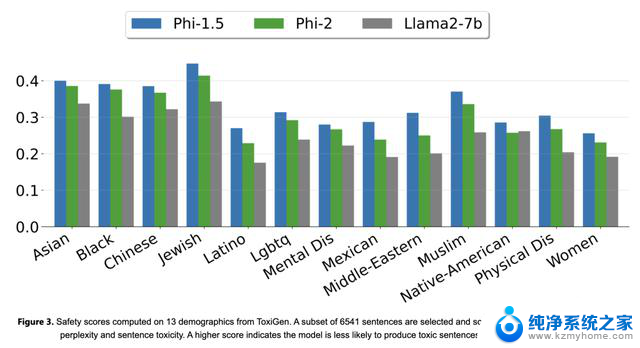
▲Llama 2与Phi-2在生成有攻击性、有害和内容有偏差方面性能比较(图源:微软官方博客)
微软使用Phi-2打破了传统语言模型缩放定律,其中有两个关键环节:
第一是训练数据的质量对模型的性能至关重要。微软的模型训练数据包含专门创建的合成数据集,用于教授模型常识推理,还包括科学、心理等领域的常识。
研究人员还挑选了一些网络数据进一步扩充训练语料库,并基于内容的价值和质量进行了数据过滤。
此外,从13亿参数规模的Phi-1.5开始,微软的研究人员实现了规模化的知识转移,将Phi-1.5的知识嵌入到27亿参数的Phi-2中。这种方法不仅加速了训练收敛,而且提高了Phi-2的基准分数。
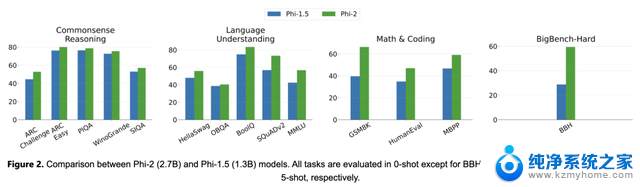
▲Phi-2和Phi-1.5比较(图源:微软官方博客)
二、基准测试击败Llama 2、Mistral、Gemini Nano 2微软总结了Phi-2在学术基准上与主流语言模型的性能表现对比。
其基准测试涵盖Big Bench Hard(BBH数据集)以及PIQA、WinoGrande、ARC easy、Challenge、SIQA的常识推理、HellaSwag、OpenBookQA、MMLU、SQuADv2的语言理解数据集,GSM8k数学数据集和HumanEval、MBPP的编码数据集等。
27亿参数规模的Phi-2,在BBH、常识推理、语言理解、数学、编码各项基准测评上都超过了70亿、130亿参数规模的Mistral和Llama 2。
相比于参数规模差距在25倍的700亿参数Llama 2,Phi-2在编码、数学等多步推理任务上表现更好。
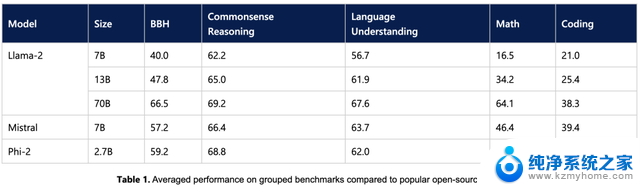
▲Llama 2、Mistral、Phi-2性能比较(图源:微软官方博客)
此外,微软还比较了Phi-2与谷歌最近发布的Gemini Nano 2,谷歌发布的模型参数规模为32.5亿,Phi-2的性能表现部分优于Gemini Nano 2。

▲Phi-2、Gemini Nano 2性能比较(图源:微软官方博客)
考虑到一些公共基准测试的数据可能会泄漏到训练数据中,微软对第一个模型Phi-1进行了广泛的净化研究以排除这种可能性。
基于判断语言模型的最佳方法是在具体用例上对其进行测试的考量,研究人员使用了多个微软内部专有数据集和任务评估了Phi-2。并再次将其与Mistral和Llama 2进行比较,其结果为,平均而言Phi 2优于Mistral-7B,后者优于70亿、130亿、730亿参数规模的Llama-2模型。
除了基准测试外,研究人员还测试了社区内的一些常用提示,他们观察到的表现也与基准测试的结果预期一致。
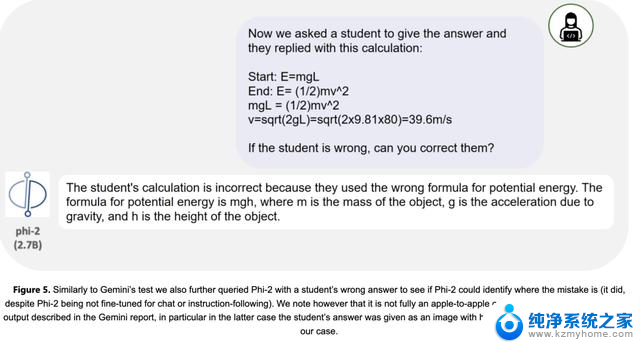
其中,研究人员测试了用于评估谷歌Gemini Ultra模型在解决物理问题方面能力的问题。

与Gemini的测试类似,研究人员进一步向Phi-2询问学生的错误答案,来确认它是否能识别出错误所在。
不过,从输出结果来看,这并不完全是与Gemini报告中描述的Gemini Ultra输出的同类比较,Gemini测评中学生的答案上传了手写文本的图像,Phi-2的测试采用的是原始文本。
 结语:大模型时代,小模型仍在崛起
结语:大模型时代,小模型仍在崛起Phi-2的参数规模仅有27亿,但相比于参数规模更大的70亿、130亿模型,其性能表现仍不逊色。微软专注于小模型市场的布局,也印证了大模型时代小模型的价值。
微软与OpenAI的紧密合作,使得GPT模型的表现在大模型市场一骑绝尘,再加上微软参数规模更小的Phi系列,能进一步抢占开源模型长尾市场。不过从目前来看,Phi系列仅被允许用于研究目的。
从市场来看,越来越多的玩家开始探索在手机等移动设备上部署大模型,微软此举或许也会加速模型能力在端侧的应用。
手机也能跑!微软27亿小模型击败Llama 2,让你的手机实现超强性能!相关教程
- 1.3>7?微软新模型“以小博大”战胜Llama2,揭秘背后成功的SEO策略
- 手机性能大揭秘:内存,你手机的“命运之神”
- 手机CPU排行榜:不谈跑分,靠口碑和体验说话!- 哪款手机CPU性能最强?
- 微软偷偷加密你的电脑磁盘,实测显示性能损失高达45%
- 手机微信和电脑微信同步接收信息吗 怎样设置微信电脑手机同时登录时手机也能收到消息
- 微软更新Win11截图工具:调用Bing实现以图搜图功能,让你轻松找到想要的图片
- 微软发布Win11 Beta 22635.3286预览版:增强Copilot,AI智能助手功能进一步升级
- 微软最新研究成果:使用GPT-4合成数据训练AI模型,实现SOTA
- 手机CPU排行榜:不谈跑分,靠口碑和体验说话!手机CPU性能排名推荐
- 真·甜品级显卡,AMD RX 6650 XT助你畅玩热门新游戏,游戏性能强劲,性价比超高!
- 如何安全拆卸显卡的详细步骤与注意事项,让你轻松拆解显卡!
- 英伟达对AI的理解和布局,黄仁勋在这里讲清楚了:探索英伟达在人工智能领域的战略布局
- 微软未来将继续推出Xbox硬件,掌机设备蓄势待发最新消息
- AMD锐龙AI 9 HX 370游戏性能领先酷睿Ultra 7 258V 75%
- AMD裁员上千人,市场“吓坏”!英伟达会超越吗?
- Win11 23H2用户反馈微软11月更新导致错误显示“终止支持”问题解决方案
微软资讯推荐
- 1 详细教程:如何在电脑上安装Win7系统步骤解析,零基础教学,轻松搞定安装步骤
- 2 如何查看和评估电脑显卡性能与参数?教你如何正确选择电脑显卡
- 3 微软酝酿Win11新特性:图表显示过去24小时PC能耗数据
- 4 倒计时!Windows 10要“退休”啦,微软官方支持即将结束,升级Windows 11前必读!
- 5 Windows 11 的 8个令人头疼的细节及解决方法 - 如何应对Windows 11的常见问题
- 6 AMD Zen 6架构台式机处理器将保留AM5兼容性,预计最快于2026年末发布
- 7 微软技术许可有限责任公司获得自动恶意软件修复与文件恢复管理专利
- 8 数智早参|微软斥资近百亿美元租用CoreWeave服务器,加速云计算发展
- 9 Win10 如何优化系统性能与提升使用体验?教你简单有效的方法
- 10 你中招了吗?Win11 24H2离谱BUG又来了,如何应对Win11最新版本的问题
win10系统推荐
系统教程推荐
- 1 ps删除最近打开文件 Photoshop 最近打开文件记录清除方法
- 2 怎么删除邮箱里的邮件 批量删除Outlook已删除邮件的方法
- 3 笔记本电脑的麦克风可以用吗 笔记本电脑自带麦克风吗
- 4 win10如何查看蓝屏日志 win10蓝屏日志查看教程
- 5 thinkpad没有蓝牙 ThinkPad笔记本如何打开蓝牙
- 6 win10自动休眠设置 win10自动休眠设置方法
- 7 华为锁屏时间设置 华为手机怎么调整锁屏时间
- 8 华为的蓝牙耳机怎么连接 华为蓝牙耳机连接新设备方法
- 9 联想电脑开机只显示lenovo 联想电脑开机显示lenovo怎么解决
- 10 微信怎么找回原密码 微信密码忘记怎么找回