干翻英伟达,总共分几步?实用攻略

上周,谷歌发布了自家最新(第七代)TPU芯片Ironwood。圈里又冒出来一堆炸裂体的文章,讲这颗芯片如何干翻英伟达…
实际情况怎么样呢?先说结论:毫无机会。
今天我们就来简单分析下,谷歌要想在AI芯片领域干翻英伟达,总共分几步?
虽然是挂谷歌举例子,但也同样适用于圈里所有玩家。包括悄悄发力、跃跃欲试甚至希望遥遥领先的国产厂商们↓
干翻英伟达,只需要五步❶搞定芯片性能:
单拼芯片本身,Ironwood确实有点儿东西,尤其在FP8推理、内存容量和功耗效率上,与Blackwell旗鼓相当。
但仅仅看推理场景,英伟达在低精度(FP4)和混合精度任务中的优化,以及集群互联技术的成熟度,仍然优势明显。更不用说高精度和训练场景。
当然,仅仅是谷歌这一小步,对国产芯片厂商已经很有难度了。不过Ironwood的思路值得借鉴,那就是锁定推理场景,提升能效比,争取局部领先。
另外,只要我们的芯片性能超过阉割版,就算是成功的第一步。
❷打破生态壁垒:
即便芯片性能过关,这一步更难。
英伟达的CUDA和软件栈是AI开发的行业标准,谷歌的TPU生态(JAX、TensorFlow)覆盖面有限,短期内难以吸引大量开发者迁移。
国内芯片同样存在这样的尴尬,计算平台、AI框架、开发工具链都需要慢慢积累。
❸消除市场惯性:
英伟达的GPU已在80-90%的AI工作负载中占据主导,客户切换成本高,Ironwood的云端专属模式进一步限制了其吸引力。
谷歌的困境也是国产AI芯片的困境,毕竟客户不爱吃螃蟹,对国内利好的一点是芯片禁运和信创需求,可以推动客户切换。
❹解锁全栈能力:
英伟达的GPU全面覆盖训练、推理和边缘计算,适用场景更广;Ironwood主要在推理上优化,无法对抗英伟达的全栈优势。
从未来趋势看,推理是大需求,训练是小需求,国内AI芯片如果能主攻推理(FP8/FP6/FP4),不追求训练核弹,未尝不是更好的出路。
当然低精度高速度反而对器件和工艺的要求更高,更难做。所以千万不要小看N家的低精度推理优势。
❺持续迭代创新:
英伟达已明确从两年一次的架构更新转向每年推出一款新芯片的节奏。
2025年下半年将推出Blackwell Ultra,2026年推出Vera Rubin,2027年推出Rubin Ultra,性能预计比Hopper架构提升数十倍,目标支持万亿参数模型的实时推理和训练。
这种节奏,谷歌跟不上,业内也没有厂商跟得上,不过N记的多芯片设计和先进制程依赖TSMC,有一定供应链风险(当然,国产芯片供应链风险更大,即便已经正在慢慢破局)。
总而言之,虽然英伟达AI芯片面临AMD Instinct MI系列、Intel Gaudi 3和谷歌TPU等竞品在性能和成本上逐步追赶,客户可能转向多元化采购。
国内厂商也在不断蓄力,力求局部替代,但综合性能、生态、市场、场景、可持续性来看,每一步都任重道远。
太长不看的分界线,以下为详细分析第一战:性能战
Ironwood是谷歌首款专门针对推理优化的TPU,旨在满足生成式AI和复杂推理模型(比如MoE模型)的计算需求。关键技术亮点如下:
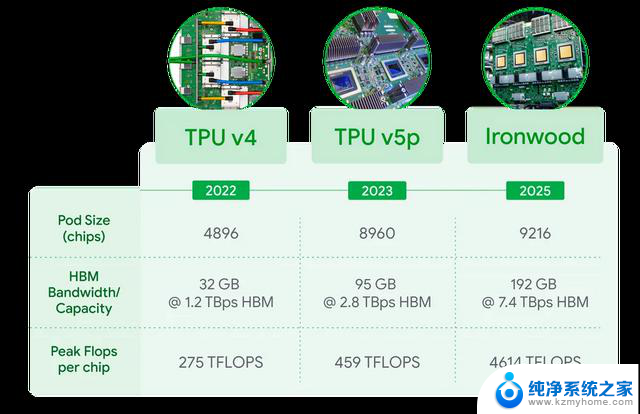
单芯片峰值性能为4,614 TFLOPs(FP8精度),集群规模可扩展至9,216个芯片,提供42.5 Exaflops的计算能力。
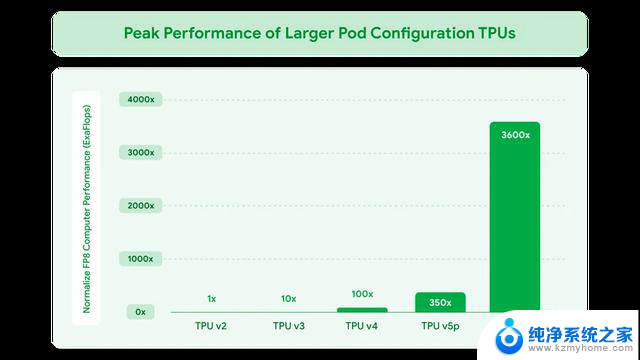
谷歌声称这一性能是全球最强大超级计算机El Capitan(1.7 Exaflops,FP64精度)的24倍以上。听起来很NB吧,但谷歌这里玩了数字游戏,拿FP8与FP64的比较,有点不讲武德。
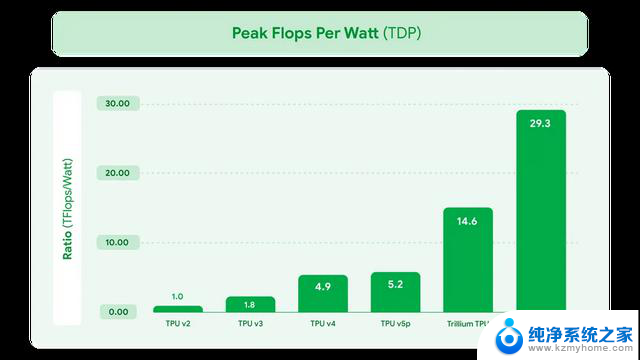
Ironwood相比前代Trillium(第六代TPU),每瓦性能提升2倍,跟第一代TPU比,更是提升3,600倍,功耗效率提升近30倍。
每芯片配备192GB高带宽内存(HBM),是Trillium的6倍,带宽达7.2-7.4 TB/s。
增强的芯片间互联(ICI)带宽达1.2 Tbps(双向),比Trillium提升1.5倍,支持大规模同步通信。(ICI相当于谷歌的NVlink)
单项PK,英伟达的比较:
Ironwood单芯片4,614 TFLOPs@FP8与英伟达B200(4,500 TFLOPs@FP8)性能相当,但B200在FP4精度下可进一步提升吞吐量(适合低精度推理)。
Ironwood的9,216芯片集群(42.5 EFLOPs)在理论峰值上领先,但英伟达的NVL144集群可以提供更高FP4性能。
同时,英伟达的NVLink和NVSwitch互联技术在高密度集群中表现出色,在分布式任务中优于谷歌的ICI。
显存方面,Ironwood的192GB HBM和7.2 TB/s带宽领先于B200(141GB HBM3e,4.8 TB/s带宽),对内存密集型推理任务(如长上下文LLM)更有优势。
但英伟达在HBM3e技术上更灵活,支持Micron等供应商,在供应链稳定性上占优。
Ironwood的能效比优于B200,尤其在FP8推理任务中,但英伟达在FP4和稀疏计算优化上仍有领先。
不过,英伟达的Blackwell平台整体功耗偏高(单卡约700W),堪称电老虎,可能在超大规模部署中面临电力瓶颈。
而Ironwood在能效比上,还是占据了一定优势。
小结一下↓
从技术角度看,Ironwood在FP8推理性能、内存容量和功耗效率上与英伟达Blackwell系列旗鼓相当,甚至在特定场景(如内存密集型推理)略有优势。
英伟达在低精度(FP4)和混合精度任务中的优化,以及集群互联技术的成熟度,仍使其在多样化AI工作负载中更具竞争力。
纯看推理,谷歌这款芯片还比较能打,这一局算是基本打平吧。

第二战:市场与应用场景战
Ironwood的定位是推理优先和云端专属。
Ironwood是谷歌首款专为推理设计的TPU,针对生成式AI的实时响应需求。推理正成为AI工作负载的主导部分,谷歌这波操作很应景。
同时,Ironwood仅通过Google Cloud提供(256或9,216芯片配置),不对外销售硬件,锁定云服务生态。

从目标客户看,支持Gemini、AlphaFold等前沿模型,同时吸引生成式AI初创企业和需要超大规模推理的客户,比如苹果曾用8,192个TPU v4训练其基础模型。
英伟达的定位则是全栈覆盖,硬件销售+云服务并举,其GPU同时支持训练和推理,覆盖从云端到边缘的广泛场景。
销售模式不仅提供GPU硬件,还与云大厂合作,提供GPU实例,市场覆盖更广。比如云头牌AWS,就推出了英伟达GPU实例全家桶。
而国内云,只要不受限的,也都会把英伟达GPU作为首选。
Ironwood高度集成于谷歌生态,适合依赖Google Cloud的客户,但灵活性太低。
而英伟达的开放生态支持多种框架(TensorFlow、PyTorch)和部署环境,适应性更强。
所以,这一局,谷歌完败。

第三战:生态与软件支持战
Ironwood与谷歌Pathways运行时、JAX和Vertex AI深度整合,支持Gemini、Llama等模型。Pathways可高效分布式计算、跨数万TPU协同工作。
但是,TPU生态相对封闭,严重依赖谷歌的TensorFlow和JAX框架,PyTorch支持有限。(虽然vLLM近期宣布支持TPU)
谷歌云提供一站式AI服务,对初创企业吸引力较大。
反观英伟达,CUDA、TensorRT、Triton Inference Server和NAIE套件支持几乎所有主流AI框架,开发者体验更优。

同时有庞大开发者社区和第三方优化,模型迁移成本低,跨平台兼容性强。
从灵活性看,英伟达的GPU可在几乎所有云服务上部署,以及本地部署,客户选择余地更大。(买不起和买不到的另当别论)
这一局,谷歌仍然毫无取胜机会。

第四战:成本与价格战
谷歌并未公开Ironwood的定价,但TPU历来以高性价比著称,尤其在Google Cloud上运行大规模推理任务时。同时,Ironwood的能效比很不错。
可是这一切的前提是:客户需完全依赖Google Cloud,初期迁移成本(如模型优化、框架适配)可能较高。
英伟达GPU价格较高,就不用说了,贼贵。

但其性能通用性、易用性和生态优势抵消了部分成本劣势,可以大大降低客户踩坑成本,毕竟填坑的隐形成本更高。
还有一点,英伟达现在开始推FP4推理优化了,有机会进一步降低推理成本,尤其在边缘场景中。
这一局,仍然是英伟达的优势局。

第五战:产品迭代能力战
谷歌的优势在于自研生态垂直整合(从芯片到模型再到云服务的全栈),优化深度推理任务。
同时自有数据中心规模巨大,自己吃狗粮就ok,同时目前大规模需求都是推理,Ironwood的定位恰好精准。

但是英伟达的客户基础和开发者社区难以撼动,短期内Ironwood难以引发大规模切换。
更重要的是,英伟达的产品迭代能力,犹如已经提速的跑车,后来者很难追赶。
比如,英伟达已明确从两年一次的架构更新转向每年推出一款新芯片的节奏。
2025年下半年将推出Blackwell Ultra,2026年推出Vera Rubin,2027年推出Rubin Ultra,性能预计比Hopper架构提升数十倍,目标支持万亿参数模型的实时推理和训练。

所以,谷歌的Ironwood更适合在推理领域切分市场份额,但其云端专属模式很难与英伟达直接精准。
其他玩家(如AMD的MI300X、AWS的Trainium、Intel的Gaudi、以及菊厂的昇腾910)虽然也在挑战英伟达,但短期内很难形成足够威胁。
所以,干翻英伟达只需要五步,但是每一步都堪比登天路。

干翻英伟达,总共分几步?实用攻略相关教程
- 英伟达和英特尔推出改良版芯片,产业链人士证实属实
- GDDR7显存亮相GTC,英伟达50系部分选用G7显存情况揭秘
- 继续狙击英伟达,AMD子弹已上膛丨焦点分析: AMD如何成为英伟达的竞争对手?
- 英伟达对AI的理解和布局,黄仁勋在这里讲清楚了:探索英伟达在人工智能领域的战略布局
- 英伟达AI新课爆火!免费学习,干货满满-立即报名,提升技能
- 英伟达再战移动掌机,这次要靠AI逆风翻盘?最新动态揭秘
- OpenAI改变策略:英伟达根本逻辑受影响?撒谎者是谁?
- AMD、英特尔AI业务未达预期股价大跌!英伟达能否拯救局面?
- 因为英伟达,半导体行业步入“新战国时代”?英伟达如何推动半导体行业进入新时代
- 消息称英伟达将推RTX 4080 Ti显卡,与4080同价-最新英伟达4080 Ti显卡消息
- 怎么测试显卡稳定性?教你几种简单有效的方法
- 美国全面封锁!NVIDIA、AMD、Intel的AI芯片非许可禁止销售到中国
- Windows 11 更新再爆蓝屏危机:微软紧急发布修补方案,如何解决蓝屏问题?
- 瑞银:微软数据中心投资放缓,目标价调整至480美元
- 微软win11更新后强制联网激活如何绕过?详细教程
- 微软警告:Outlook打字竟让CPU“爆表”,如何解决?
微软资讯推荐
- 1 Windows 11 更新再爆蓝屏危机:微软紧急发布修补方案,如何解决蓝屏问题?
- 2 瑞银:微软数据中心投资放缓,目标价调整至480美元
- 3 干翻英伟达,总共分几步?实用攻略
- 4 微软win11更新后强制联网激活如何绕过?详细教程
- 5 微软警告:Outlook打字竟让CPU“爆表”,如何解决?
- 6 英伟达突袭“美国造”:投桃报李还是避税有道?
- 7 Nvidia投资5000亿欲建AI芯片全产业链,加速推动人工智能技术创新
- 8 详细教程:如何在电脑上安装Win7系统步骤解析,零基础教学,轻松搞定安装步骤
- 9 如何查看和评估电脑显卡性能与参数?教你如何正确选择电脑显卡
- 10 微软酝酿Win11新特性:图表显示过去24小时PC能耗数据
win10系统推荐
系统教程推荐
- 1 win11键盘突然变成快捷键 win11键盘快捷键取消方法
- 2 windows10复制文件需要管理员权限 如何解决需要管理员权限才能复制文件夹的问题
- 3 右键新建没有ppt怎么办 Win10右键新建菜单中没有PPT如何添加
- 4 打开电脑触摸板 win10触摸板功能开启
- 5 多个word在一个窗口打开 Word如何实现多个文件在一个窗口中显示
- 6 浏览器分辨率怎么调整 浏览器如何设置屏幕分辨率
- 7 笔记本电脑开不了机怎么强制开机 笔记本电脑按什么键强制开机
- 8 怎样看是不是独立显卡 独立显卡型号怎么查看
- 9 win11电脑唤醒不了 Win11睡眠无法唤醒怎么解决
- 10 无线网络密码怎么改密码修改 无线网络密码如何更改