微软论文曝出GPT-3.5参数仅有200亿,网友大呼太离谱!
GPT-3.5只有200亿参数?
今天,大模型圈都被微软论文中的一纸截图刷爆了,究竟是怎么回事?
就在前几天,微软发表了篇论文并挂在了arXiv上,该论文提出了一个参数量只有75M的小规模扩散模型——CodeFusion。
性能方面,7500万参数的CodeFusion在top-1准确率指标上,可以与最先进的350M-175B模型相媲美。

论文地址:https://arxiv.org/abs/2310.17680
这篇论文的工作很有意义,但引起大家格外注意的却是——
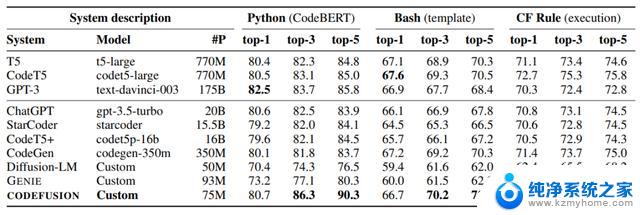
作者在对比ChatGPT(gpt-3.5-turbo)时,标称的参数量竟然只有20B!
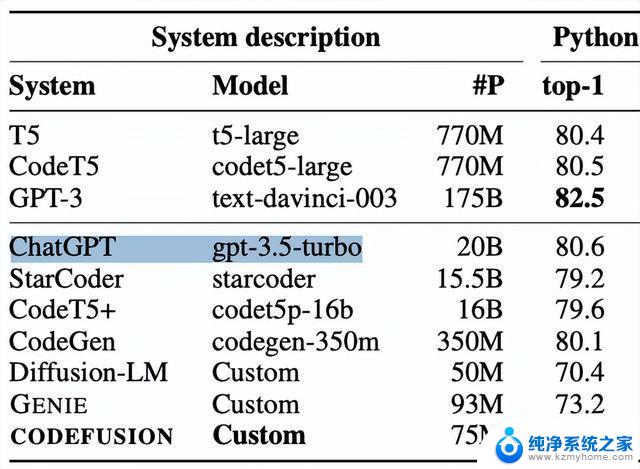
在此之前,大家针对GPT-3.5参数量的猜测都是1750亿,这相当于是缩减了差不多十倍!
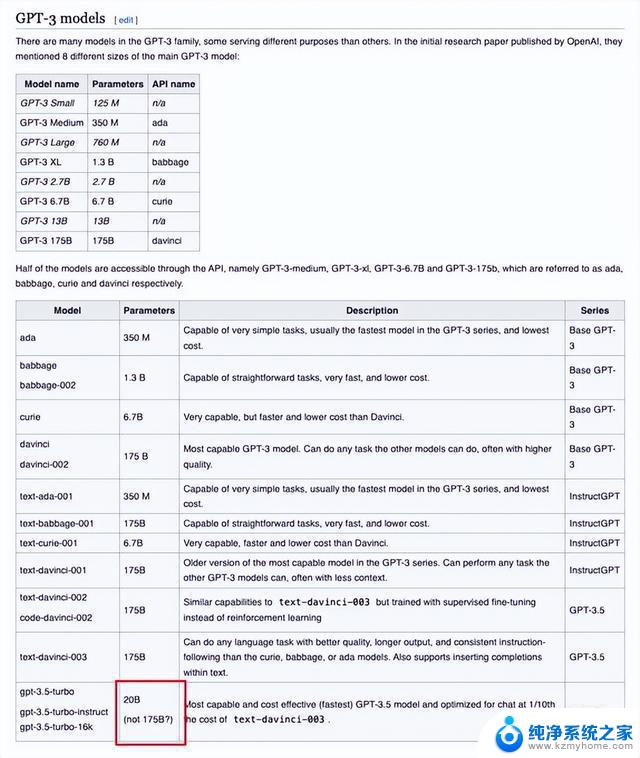
根据这篇论文的爆料,网友还去维基百科上更新了GPT-3.5的介绍,直接把参数大小改成了20B。
消息一出,直接登上知乎热搜,网友们都炸了。

有人表示,赶紧回头再把我之前模型蒸馏的博文拿出来复习复习 。

是「乌龙」还是「事实」?
网友的爆料贴一出,瞬间就引发了激烈的讨论。
目前,已经有超过68万人前来围观。
这位老哥表示,论文的几位作者也都在用推特,估计过不了多久就会亲自下场解释。

而对于这个神秘的「20B」,网友们也是众说纷纭。

有人猜测,这很可能是作者手误打错了。比如原本是120B,或者200B。

结合现实中的各项评测来看,确实有很多小模型能够取得和ChatGPT差不多的成绩,比如Mistral-7B。

也许,这也是侧面证实了GPT-3.5体量真的不大。
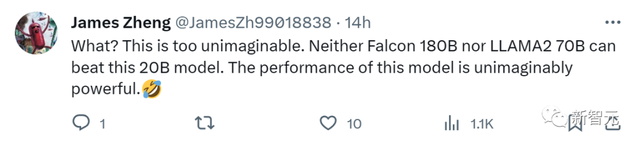
很多网友也认为20B的参数可能是准确的,纷纷发出感叹:
「这也太难以想象了!Falcon-180B和Llama2-70B,竟然都无法击败这款20B的模型。」
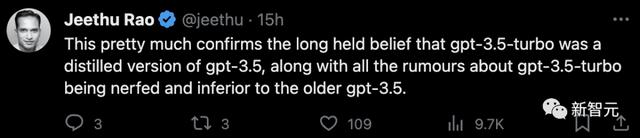
也有网友认为,gpt-3.5-turbo是精炼版的gpt-3.5。
而这次参数的「泄露」,正好从侧面印证了那些关于gpt-3.5-turbo表现不如旧版gpt-3.5的传言。
不过,根据OpenAI的官方文档,除了已经不再使用的text-davinci和code-davinci,GPT-3.5家族全员都是基于gpt-3.5-turbo构成的。



微软发布CodeFusion
而爆出GPT3.5只有20B参数的微软论文,是想介绍一个用于代码生成的扩散模型。
研究人员针对Bash、Python和Microsoft Excel条件格式(CF)规则的自然语言生成代码的任务来评估这个模型——CodeFusion。
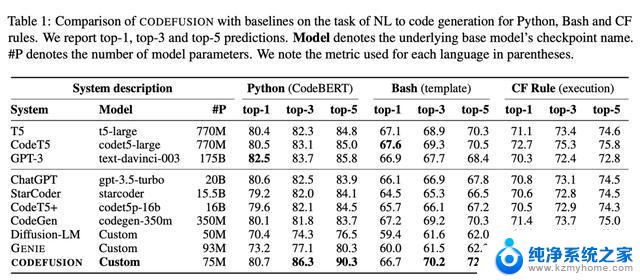
实验表明,CodeFusion(只有75M参数)在top-1精度方面与最先进的LLM(350M-175B参数)相当。并且在top-3和top-5精度方面性能和参数比非常优秀。
模型架构
CODEFUSION用于代码生成任务,它的训练分为两个阶段,第一阶段是无监督预训练,第二阶段是有监督微调。
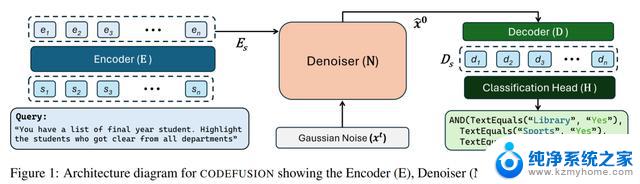
在第一阶段,CODEFUSION使用未标记的代码片段来训练降噪器和解码器。它还使用可训练的嵌入层L,将代码片段嵌入到连续空间中。
在第二阶段,CODEFUSION进行有监督的微调,使用来自文本-代码对数据。在这个阶段,编码器、降噪器和解码器都会得到调整,以更好地执行任务。
此外,CODEFUSION还借鉴了之前有关文本扩散的研究成果,将来自解码器的隐藏表示D融合到模型中。这是为了改进模型的性能。在训练过程中,在不同step中,模型引入一些噪声,然后计算损失函数,以确保生成的代码片段更符合预期的标准。
总之,CODEFUSION是一个执行代码生成工作的小模型,通过两个阶段的训练和噪声引入来不断提升其性能。这个模型的灵感来自于文本扩散的研究,并通过融合解码器的隐藏表示来改进损失函数,以更好地生成高质量的代码片段。
评估结果下表总结了CODEFUSION模型与各个基线模型在top-1、top-3和top-5设置下的性能表现。
在top-1中,CODEFUSION的性能与自回归模型相媲美。甚至在某些情况下表现更出色,尤其是在Python任务中,只有GPT-3(175B)的性能稍微优于CODEFUSION(75M)。然而,在top-3和top-5方面,CODEFUSION明显优于所有基线模型。
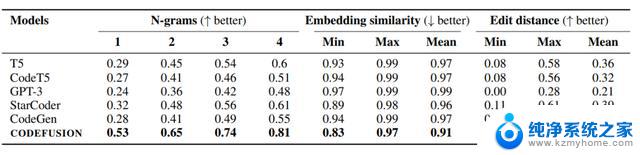
表下表展示了CODEFUSION和自回归模型(包括T5、CodeT5、StarCoder、CodeGen、GPT-3)在各项基准任务上的平均多样性结果,考察了每个模型的前5代生成结果。
相对于自回归模型,CODEFUSION生成更加多样化的结果,表现更出色。
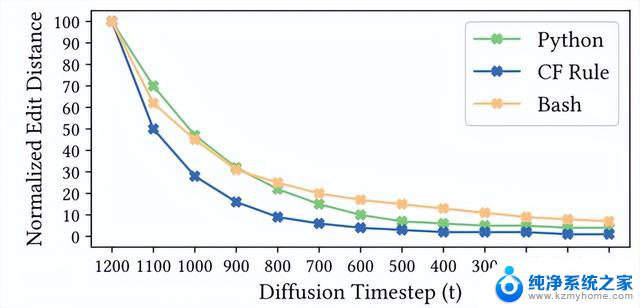
在消融实验中,作者停止了去噪过程,并生成了在时间步t∈[0, T]范围内的当前状态的代码片段。利用归一化字符串编辑距离来衡量每个时间步长(每100步为一个增量)所获得的结果。
这一方法有助于总结和展示CODEFUSION模型的逐步进展,如下图所示。
说了这么多,GPT-3.5的参数量到底是多少?GPT-4与GPT-3.5在技术和其他方面有着什么样的联系?
GPT-3.5是一个个小专家模型的集成还是一个通才模型?是通过更大模型的蒸馏还是更大数据训练?
这些问题的答案只能等到真正开源的时候才能揭晓了。
参考资料:
https://arxiv.org/abs/2310.17680
https://twitter.com/felix_red_panda/status/1718916631512949248
微软论文曝出GPT-3.5参数仅有200亿,网友大呼太离谱!相关教程
- 微软将推出自研 5000 亿个参数的大模型:MAI-1,领先AI技术发展趋势
- 数智早参|微软斥资近百亿美元租用CoreWeave服务器,加速云计算发展
- 文档中字与字之间的距离太宽了 Word文档字间距过大原因
- 道指涨超200点,微软、英伟达创收盘历史新高!中概股大涨!
- GPT-4太烧钱!微软撑不住了,被曝悄悄启动Plan B:微软为何决定转变策略?
- 微软超越OpenAI成为全球第四大AI公司,估值高达288亿
- 你中招了吗?Win11 24H2离谱BUG又来了,如何应对Win11最新版本的问题
- 微软市值达3万亿美元,科技霸主再创辉煌!微软称霸科技领域,市值达3万亿美元!
- 英伟达Q3收入增长超200%:中国数据中心产品无需出口许可证
- 微软文件披露:新入职员工起步4.25万美元,职位待遇曝光
- 如何安全拆卸显卡的详细步骤与注意事项,让你轻松拆解显卡!
- 英伟达对AI的理解和布局,黄仁勋在这里讲清楚了:探索英伟达在人工智能领域的战略布局
- 微软未来将继续推出Xbox硬件,掌机设备蓄势待发最新消息
- AMD锐龙AI 9 HX 370游戏性能领先酷睿Ultra 7 258V 75%
- AMD裁员上千人,市场“吓坏”!英伟达会超越吗?
- Win11 23H2用户反馈微软11月更新导致错误显示“终止支持”问题解决方案
微软资讯推荐
- 1 详细教程:如何在电脑上安装Win7系统步骤解析,零基础教学,轻松搞定安装步骤
- 2 如何查看和评估电脑显卡性能与参数?教你如何正确选择电脑显卡
- 3 微软酝酿Win11新特性:图表显示过去24小时PC能耗数据
- 4 倒计时!Windows 10要“退休”啦,微软官方支持即将结束,升级Windows 11前必读!
- 5 Windows 11 的 8个令人头疼的细节及解决方法 - 如何应对Windows 11的常见问题
- 6 AMD Zen 6架构台式机处理器将保留AM5兼容性,预计最快于2026年末发布
- 7 微软技术许可有限责任公司获得自动恶意软件修复与文件恢复管理专利
- 8 数智早参|微软斥资近百亿美元租用CoreWeave服务器,加速云计算发展
- 9 Win10 如何优化系统性能与提升使用体验?教你简单有效的方法
- 10 你中招了吗?Win11 24H2离谱BUG又来了,如何应对Win11最新版本的问题
win10系统推荐
系统教程推荐
- 1 ps删除最近打开文件 Photoshop 最近打开文件记录清除方法
- 2 怎么删除邮箱里的邮件 批量删除Outlook已删除邮件的方法
- 3 笔记本电脑的麦克风可以用吗 笔记本电脑自带麦克风吗
- 4 win10如何查看蓝屏日志 win10蓝屏日志查看教程
- 5 thinkpad没有蓝牙 ThinkPad笔记本如何打开蓝牙
- 6 win10自动休眠设置 win10自动休眠设置方法
- 7 华为锁屏时间设置 华为手机怎么调整锁屏时间
- 8 华为的蓝牙耳机怎么连接 华为蓝牙耳机连接新设备方法
- 9 联想电脑开机只显示lenovo 联想电脑开机显示lenovo怎么解决
- 10 微信怎么找回原密码 微信密码忘记怎么找回