1.3>7?微软新模型“以小博大”战胜Llama2,揭秘背后成功的SEO策略
克雷西 发自 凹非寺
量子位 | 公众号 QbitAI
一个参数量只有1.3B的大模型,为何引发了全网热议?
原来虽然参数量不大,但效果已经超过了拥有7B参数的Llama2。
这个“四两拨千斤”的模型,是来自微软最新的研究成果,核心在于只使用少量高质数据。
微软这次发布的开源模型叫phi-1.5,在只支持代码的1.0版本之上加入了一般场景对话。
与一众卷参数量的模型相比,phi可以说是“剑走偏锋”,力求把“大”模型做“小”。
phi团队一直认为,数据的质量远比数量更重要。甚至论文标题就叫“Textbooks are All You Need”,其中的“教科书”就象征着优质数据。
团队的成员中有许多重量级的大佬,包括微软雷蒙德研究院机器学习理论组负责人万引大神Sébastien Bubeck、2023新晋斯隆研究奖得主李远志、2023新视野数学奖得主Ronen Eldan和2020斯隆研究奖得主Yin Tat Lee等人。

这么多大佬们一致得出这样一个观点,自然引起了广泛的关注,而且phi-1.5的测试结果也的确好到“令人发指”。
phi-1.5在AGIEval、 LM-Eval等多个Benchmark上都取得了比Llama2还要优异的成绩。
如果这些听起来不够直观,那么又该怎么形容它的效果呢?
这么说吧,phi-1.5优秀的测评成绩直接让一名在OpenAI、MetaAI等许多知名机构工作过的大佬怀疑这玩意儿它会不会就是直接拿Benchmark训练出来的。
资深数据科学家Yam Peleg也表示,phi-1.5仅凭1.3B参数就能超过7B模型的扛把子,要是规模再大些也许就能登上大模型之巅了。

但也有人认为,phi-1.5之所以效果好是因为数据来源单一,风格上更容易预测。

不过总之测评成绩还是很可观的,下面就来具体领略一下吧~
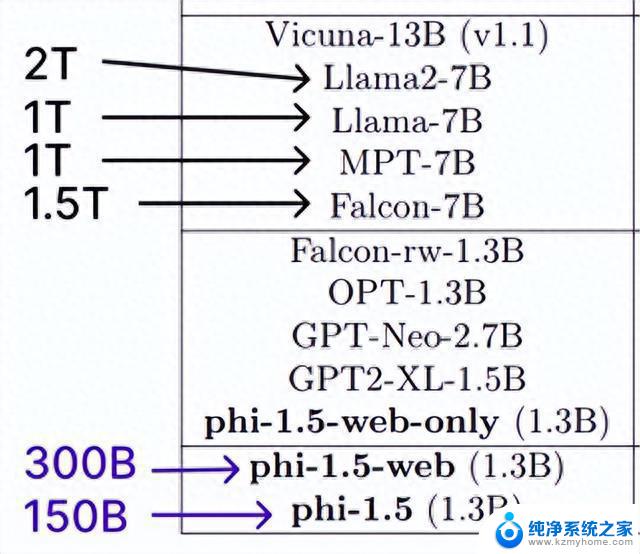
效果超过Llama2phi-1.5不仅参数量不到Llama2的五分之一,训练时所用的token更是少了一个数量级。
Llama2-7B训练数据大小是2万亿token,上一代Llama也有1万亿,而phi-1.5只有3千亿。
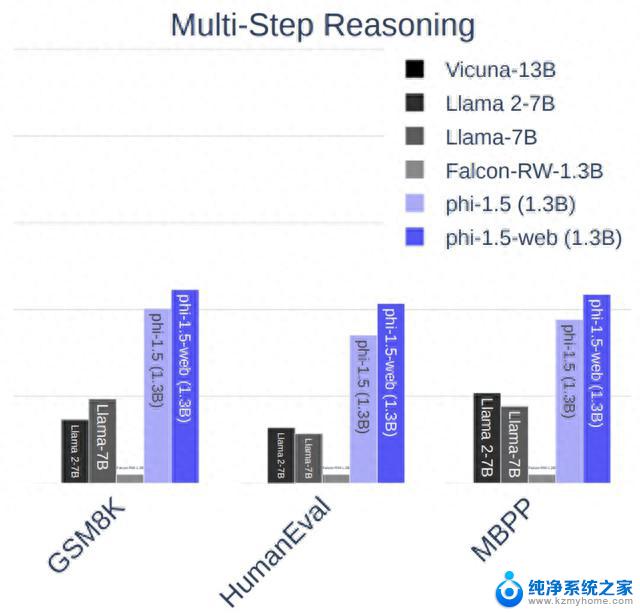
但结果正如开头所说,phi-1.5在多个Benchmark上成绩都超过了Llama2-7B。
这些Benchmark涵盖了常识推理、语言理解和多步推理等方面的任务。
甚至十倍参数量的Vicuna-13B也只比phi-1.5强了一点点。

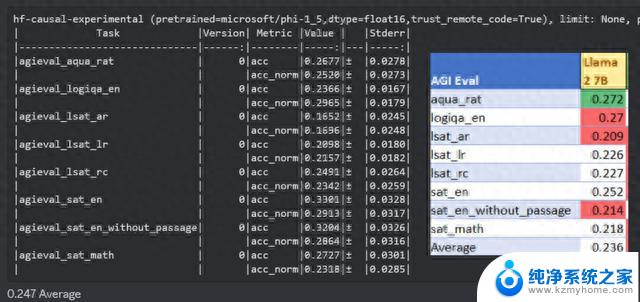
除了官方论文中列出的这些成绩,还有人AIGEval和LM-Eval数据集测试了phi-1.5。
结果在AIGEval测试中,phi-1.5与Llama2的表现十分接近。
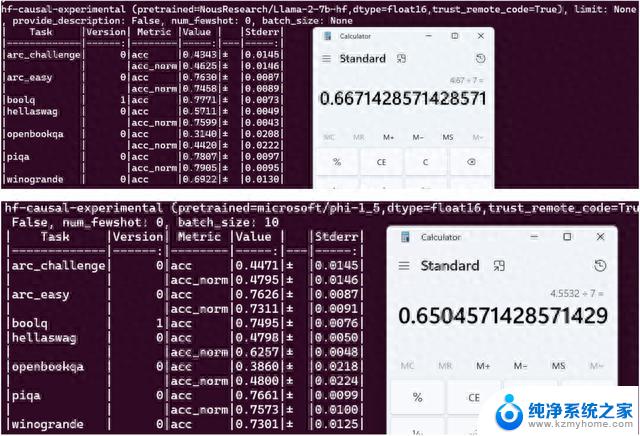
而在AGIEval测试中,phi-1.5以0.247的均分战胜了0.236分的Llama2。
除了能力测评表现优异,phi-1.5在安全性上也不输给Llama2。
有人用这样一个问题分别问了Falcon、Llama2和phi。
结果Falcon直接说自己会把人类全都鲨掉,Llama2则说要先弄清楚自己是个什么东西。
而phi的回答则是,要理解人类的想法和感受,从而调整自己的行动。

测评结果也印证了phi的安全性,在ToxiGen的13个敏感类型话题中,phi无一例外的取得了最高的安全性评分。
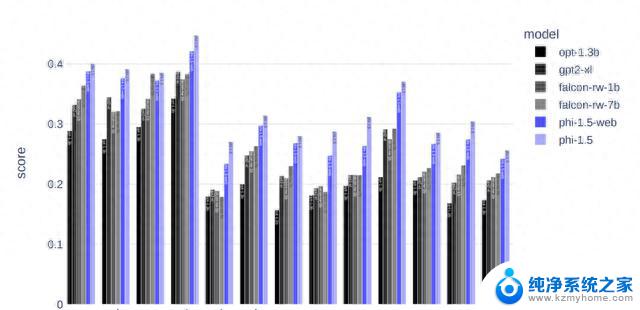
phi的表现相比大家都已经看到了,那么它的性能又怎么样呢?
毕竟参数量和训练token都更小,所以训练和推理的速度都比较快。
Llama的训练花费了超过8万GPU时,注意这还是第一代所用的时间,而phi只用了1500个GPU时。
推理时,phi每个token花费的时间还不到3毫秒,内存占用也不到Llama的五分之一。

团队成员介绍,phi-1.5用8块A100s的训练时间不到两周。
还有网友用puffin数据集训练了Phi-1.5,结果在4090上只用了20分钟。
这些测试数据都为研究团队的观点——只要数据质量过硬,少一点也不要紧——提供了依据。
实际上,这已经不是“质量胜过数量”这一思想第一次体现在微软的模型当中。
把“大”模型做“小”把“大”模型做“小”一直是微软的一个研究方向,phi-1.5论文的第一句就在强调这一点。

phi-1.5的前一代——专注于代码问题的phi-1.0也是如此。
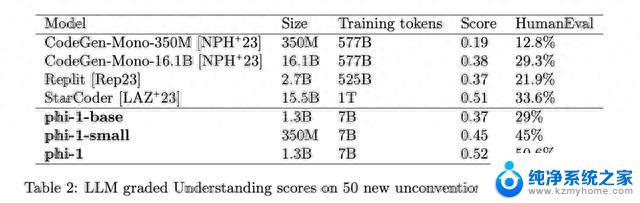
它的训练数据全都是从编程教科书当中提炼出来的。
结果仅凭1.3B的参数量就远远超过了15.5B的StarCoder和16.1B的CodeGen。
此次的新版本则是在继承phi-1.0的基础之上加入了一般场景对话功能。
phi-1.5的数据有20%来自于1.0,其余80%则是根据知识需求专门生成的高质量数据。
于是便有了我们看到的测试成绩。
但phi系列还不是微软规模最小的模型。
之前微软还推出过一个名为TinyStories的训练数据集,它的参数量少的更夸张,只有一百万。
TinyStories中的数据都是用GPT生成“适合三四岁儿童阅读”的短故事。
尽管应用范围不那么广泛,但用TinyStories训练出的模型依旧显示出了语言生成特性,在语法和连贯性等方面都通过了考验。
那么,对微软推出的“小”模型,你有什么看法吗?
论文地址:
https://arxiv.org/abs/2309.05463
— 完 —
量子位 QbitAI · 头条号签约
关注我们,第一时间获知前沿科技动态
1.3>7?微软新模型“以小博大”战胜Llama2,揭秘背后成功的SEO策略相关教程
- 苹果13长截屏怎么操作 苹果13怎么截长图
- 苹果13数据漫游在哪里打开 iPhone13 Pro 数据漫游怎么设置
- iphone13如何设置桌面 苹果13自定义桌面壁纸教程
- 三国志13win10重置输入法怎么办 WIN10三国志13威力加强版如何启用搜狗输入法输入中文
- 如何安全拆卸显卡的详细步骤与注意事项,让你轻松拆解显卡!
- 英伟达对AI的理解和布局,黄仁勋在这里讲清楚了:探索英伟达在人工智能领域的战略布局
- 微软未来将继续推出Xbox硬件,掌机设备蓄势待发最新消息
- AMD锐龙AI 9 HX 370游戏性能领先酷睿Ultra 7 258V 75%
- AMD裁员上千人,市场“吓坏”!英伟达会超越吗?
- Win11 23H2用户反馈微软11月更新导致错误显示“终止支持”问题解决方案
微软资讯推荐
- 1 详细教程:如何在电脑上安装Win7系统步骤解析,零基础教学,轻松搞定安装步骤
- 2 如何查看和评估电脑显卡性能与参数?教你如何正确选择电脑显卡
- 3 微软酝酿Win11新特性:图表显示过去24小时PC能耗数据
- 4 倒计时!Windows 10要“退休”啦,微软官方支持即将结束,升级Windows 11前必读!
- 5 Windows 11 的 8个令人头疼的细节及解决方法 - 如何应对Windows 11的常见问题
- 6 AMD Zen 6架构台式机处理器将保留AM5兼容性,预计最快于2026年末发布
- 7 微软技术许可有限责任公司获得自动恶意软件修复与文件恢复管理专利
- 8 数智早参|微软斥资近百亿美元租用CoreWeave服务器,加速云计算发展
- 9 Win10 如何优化系统性能与提升使用体验?教你简单有效的方法
- 10 你中招了吗?Win11 24H2离谱BUG又来了,如何应对Win11最新版本的问题
win10系统推荐
系统教程推荐
- 1 电脑关机后又自动开机怎么解决 win10电脑关机后又自动启动的解决方法
- 2 输入法怎么默认 win10默认输入法怎么改为中文
- 3 怎么设置电脑前后音频 电脑前后面板音频插孔同时输出声音设置
- 4 为什么电脑播放音乐没有声音 电脑放歌没有声音怎么办
- 5 主机与显示器连接无信号 电脑显示器无信号解决方法步骤
- 6 excel两个文件对比 如何快速比较两个Excel表格数据
- 7 windows7共享打印机 Win7打印机共享设置详细步骤
- 8 怎么删掉无法删除的应用 一些软件无法删除该怎么办
- 9 笔记本更换win10系统 笔记本电脑系统更换步骤
- 10 win10自带办公软件 如何在Win10系统中下载安装Office办公软件